Financial institutions taking a traditional, reactionary approach to fraud detection may take weeks, months or even years to address fraudulent activity that’s accumulating within their portfolios. This is due to two main reasons:
- Financial institutions wait until the volume of incidents hits a certain threshold before investigating and taking the appropriate action.
- Fraud evolves at a faster rate than the systems tasked with detecting it, meaning financial institutions are always playing catch up.
But the longer that fraud is allowed to fester, the greater damage it can cause. And, by taking action on a case-by-case basis, financial institutions are rarely able to improve their ability to detect and prevent fraud. They merely address it and move on.
What’s needed is a more proactive, iterative approach. One that not only utilizes the vast amount of data and tooling to help inform fraud detection, but also continuously feeds intelligence back into the system to accelerate the rate at which the system can adapt to emerging forms of fraud.
This approach to fraud detection brings together fraud teams, underwriting, financial institutions and government agencies through data-sharing to break down silos and accelerate the rate of adaptation to the ever-changing fraud landscape.
It’s a continuous loop of detection and prevention that improves accuracy and increases the prevention of fraud across the industry.
Here’s a breakdown of exactly how this process works.
The Continuous Fraud Detection Feedback Loop
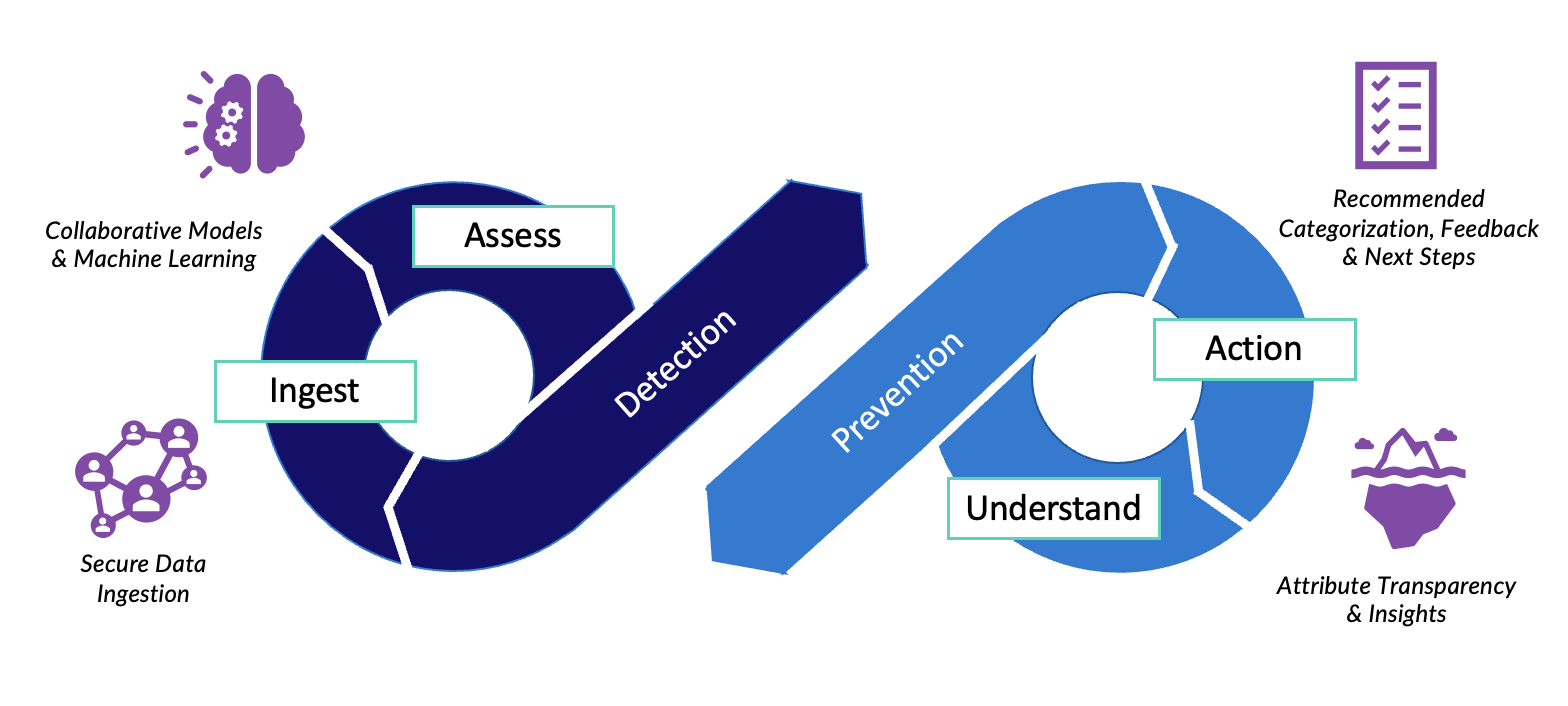
Detection
Let’s start by looking at how this approach detects financial fraud. Broadly, this part of the continuous fraud detection feedback loop is split into two sections – data ingestion and assessment.
Ingestion
To detect fraud, you need data. Financial intuitions taking a traditional approach to fraud detection are limited to internal data. That is fine, but it means they rely solely on the insights they can generate from a relatively small data set.
The continuous fraud detection methodology takes a collaborative approach whereby financial institutions and government agencies securely pool their data in a network for the collective good. If a fraudulent account is detected by one entity, it’s shared anonymously so other entities can cross-check it against their portfolios.
By ingesting data and insights from peers, financial institutions are able to exponentially increase their ability to detect fraudulent activity.
Assessment
Once an account has been flagged as fraudulent and labeled by fraud type, a “profile” is created to identify other potentially fraudulent accounts. Due to the sheer volume of attributes and their numerous combinations and patterns within a given institution, this process is automated by training machine learning models to understand and alert fraud analysts to risk.
Prevention
So, we’re ingesting as much data as possible from a range of financial institutions and government agencies, and AI is assessing any fraudulent accounts and providing them with a risk score. While technology alone has got us this far, it’s now time to introduce the human-in-the-loop element of this methodology. The prevention part of the continuous fraud detection feedback loop is split into two sections – understanding and action.
Understanding
Some fraud detection solutions are something of a black box. They assess a financial institution’s portfolio, flag any accounts that may pose a risk, and that’s it. There’s no way of taking a peak underneath the hood to see why an account has been flagged.
But how can a user take action to address fraud if they don’t know why it’s been flagged for review? A financial institution may stipulate that any account with a risk score over a certain threshold is automatically suspended. But this causes two issues:
- Genuine accounts may be automatically suspended due to anomalous characteristics that could have been verified as legitimate by a human
- The AI models making the assessment never improve as they do not receive feedback
In contrast, the continuous fraud detection feedback loop methodology provides insight into why a risk score has been given with users able to see the underlying attributes that contribute to a score. This enables them to make an informed assessment and provide the feedback required to make improvements to the AI detection models.
Action
The continuous fraud detection feedback loop empowers users to take action by providing them with insight into why an account has been flagged for fraud. However, this approach goes one step further.
When it comes to fraud detection, there can be an overwhelming amount of data. Instead of bombarding users with information, this approach triages alerts into categories and levels of prioritization.
For example, an account that is flagged with a score of 98% is almost certainly fraudulent. A financial institution can automatically take action rather than sending it for human assessment. A score of 65% requires a greater level of human investigation. Not only because it’s a lower likelihood of fraud compared to the account with 98%, but also because it’s a perfect opportunity to train the AI model. It’s identified that the account is likely fraudulent, but it’s not certain. A human can assess the characteristics that meant the account was flagged, take the appropriate action, and provide feedback to make the AI model more accurate.
This completes the loop. Data has been ingested, it’s been assessed, the user has been able to understand the assessment, take the appropriate action, and this information is then used to improve the AI models. And, because it’s a collaborative approach using data from numerous entities, it improves at detecting fraud much quicker than a single entity ever could.
The Broader Benefits of a Continuous Fraud Detection Feedback Loop
While this approach helps financial institutions to identify fraud in their portfolios, it is also a powerful tool for preventing fraud in other ways.
Because this approach reduces the time it takes to address fraud from months or years to just weeks or days, the information it produces can be actioned across the business.
For example, a bank offers a range of products including current accounts, credit cards, insurance and savings accounts. If a user is able to see that fraudulent activity is spiking on credit card applications, they can feed this back to the relevant department for investigation. It could be that the application process is susceptible to fraud or doesn’t have stringent enough requirements. The continuous fraud detection feedback loop provides actionable information that helps financial institutions to make informed decisions that reduce fraud.
How FiVerity Enables a Continuous Fraud Detection Feedback Loop
A continuous fraud detection feedback loop is the best weapon that financial institutions have at their disposal to finally get ahead of the curve and detect ever-evolving forms of fraud.
Key to the process is the artificial intelligence used to detect fraud. Previously, financial institutions worked in isolation to create models that identify fraudulent activity. Instead, FiVerity takes a collaborative approach to combine the intelligence of these models for a superior level of detection.
FiVerity’s proprietary catalog of fraud indicators is defined through training machine learning models against hundreds of thousands of manually reviewed and labeled fraud applications from across our network of customers and partners. These collaborative baseline models infer initial risk within a customer portfolio, utilizing human-in-the-loop validation to inform and adapt fraud profiles and models for continuous score optimization that is specific to each portfolio and adapts at the speed that fraud evolves.
To learn more about how FiVerity is helping the world’s leading financial institutions to improve fraud detection and increase fraud prevention, get in touch.