Financial fraud is a multifaceted challenge that requires both vigilance and data-driven intelligence. At FiVerity, our latest research reveals intriguing connections between confirmed fraud cases across multiple financial institutions. This post aims to help financial fraud analysts unpack the nuances of fraud types, detection methods, and the power of data-driven insights for effective prevention.
Synthetic vs Identity Theft: Unpacking the Nuances
What is Synthetic Identity Fraud?
Synthetic Identity Fraud (SIF) involves criminals mixing real and fabricated information to create a new identity, often blending real Social Security Numbers with fake names or addresses.
One of the most concerning aspects of SIF is its potential to facilitate a wide range of fraud types, including account takeovers, scams, loan defaults, credit card chargebacks, and more. By meticulously blending authentic elements like Social Security Numbers with fictitious names, birthdates, or addresses, criminals can open fraudulent accounts, secure loans, make unauthorized purchases, or engage in identity theft scams, all while avoiding detection for extended periods. This adaptability and ability to operate across multiple forms of fraud make SIF a significant challenge for fraud detection and prevention efforts across various industries.
What is Identity Theft?
Contrastingly, Identity Theft is the illegal use of another person's personal information, impacting the victim immediately through unauthorized transactions or legal ramifications.
Key Differences
Understanding the key differences between SIF and Identity Theft is vital for developing targeted prevention methods.
Origin of Information
- SIF: Relies on a mix of real (often stolen) and fabricated data to create a new identity.
- Identity Theft: Uses entirely real and stolen data from an existing person.
Detection Difficulty
- SIF: Synthetic Identity Fraud (SIF) presents a unique challenge in fraud detection due to its ability to evade standard verification checks. This evasion occurs because financial institutions may inadvertently "verify" the mixture of real and fake information as a legitimate identity, especially during the origination of fraudulent accounts. Furthermore, SIF can be difficult to detect over its entire lifespan, primarily because there is often no direct consumer victim in the traditional sense. The financial institution becomes the primary target, and without a clear victim reporting unauthorized activities, detection becomes elusive.
- Identity Theft: Identity Theft is comparatively more accessible to spot, particularly after a fraudulent loan has originated, as the identity owner may notice and report unauthorized transactions. However, at the point of origination, Identity Theft can be challenging to detect if there is insufficient information on soft Personally Identifiable Information (PII) elements like phone numbers and email addresses.
What is Partial Fraud Matching?
In the realm of fraud detection, a partial match refers to instances where only a subset of a person's Personally Identifiable Information (PII) correlates with known fraudulent activities.
What Constitutes Full Fraud Matching?
Contrastingly, a full match occurs when Name-DOB-SSN aligns with details found in recognized fraud cases.
Key Points to Consider
- Fraud Classification: The efficacy of using partial or full matching techniques is contingent on the specific attributes being matched as well as the type of fraud in question. The Federal Reserved provides us with a standard FraudClassifer Model to create consistency in labeling.
- Data Reliability: The integrity of the databases used is a linchpin in the success of either matching approach. Accurate and up-to-date information is indispensable for effective fraud detection.
The capability to pinpoint both partial and full matches within your portfolio—or even across a broader network—does more than just augment fraud detection rates. It also facilitates accurate labeling of suspicious accounts, thereby enhancing future detection and prevention mechanisms. This, coupled with secure information sharing, is revolutionizing the way financial institutions operate in the realm of fraud detection. By securely sharing pertinent data and insights, FIs can greatly improve their fraud detection capabilities and confidence, streamline their investigations process, and ultimately, speed up response times to potential threats, by having a more complete view of an account's history.
Patterns and Learnings from the Network: The Reuse of Changing Account Elements to Avoid Detection
The Reuse of PII in Fraud
Our Venn diagrams reveal overlaps in PII elements and combinations, shedding light on more complex fraudulent activities.

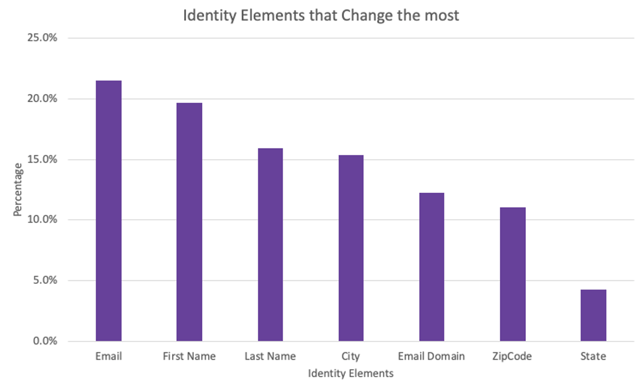
The Elements That are Reused Most Frequently
Email addresses, names, and physical addresses are the most frequently reused elements, while more difficult to change elements such as SSN and phone numbers tend to be a shared element across multiple fraudulent accounts.
The Use of Attribute Changing to Avoid Detection
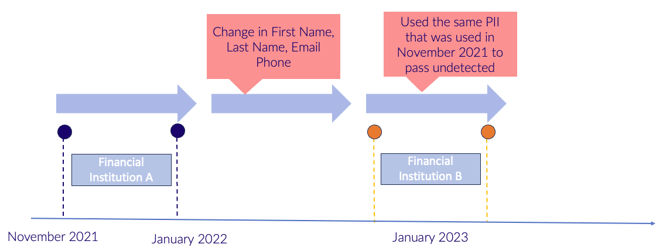
This tactic appears to be especially prevalent among sophisticated players who are well-aware of the surveillance they are under.
Simply put, attribute changing involves altering one or more elements of Personally Identifiable Information (PII) to sidestep fraud detection algorithms, either during an application process, or between multiple institutions, to maximize the use of the stolen identification elements they’ve obtained. This could mean changing email addresses, tweaking physical addresses, modifying names slightly, or using nicknames like Bob vs. Robert. This maneuver allows fraudsters to blend in with legitimate transactions and activities while carrying out their fraudulent operations at a large scale.
Why is Attribute Changing a Concern?
- Evasion of Basic Filters: Most fraud detection systems are programmed to look for exact matches or glaring inconsistencies. By altering a single attribute, fraudsters can slip through these basic filters.
- Complication of Pattern Analysis: Constantly changing attributes make it more difficult for machine learning algorithms to identify patterns indicative of fraudulent activity.
- Increased False Positives: The sporadic changes can trigger numerous false positives that require manual verification, adding an additional layer of complexity and workload for fraud analysts.
Potential Mitigation Strategies
- Dynamic Profiling: Implement a system that dynamically profiles user activity and attributes. This means not merely looking for hard matches but understanding the normal behavioral patterns of users to spot anomalies.
Source: researchgate.net
- Multi-attribute Analysis: Instead of focusing on single attributes, consider multiple attributes and their interrelations. An email change might be innocent, but if it coincides with a location change, it may require further investigation.
- Machine Learning Adaptability: Use adaptive machine learning algorithms that learn from the ever-changing tactics and update their detection protocols accordingly.
Source: aws.amazon.com
- Time-based Monitoring: Implement time-based flags where sudden changes in key attributes within a short period trigger a review.
- Human Oversight: Despite the advances in technology, the intuition of a skilled fraud analyst remains invaluable. Encourage periodic manual reviews, especially in cases that the system flags as borderline.
Manual Identification: Spotting the Unusual in the Usual
Frequent changes in PII elements that deviate from typical user behavior often warrant closer scrutiny for fraud detection.
DIY Strategies for Fraud Detection
Manual Matching: The Art of Detail-Oriented Scrutiny
- Compile a List: Gather the PII elements under investigation.
- Time-Frame Analysis: Limit the data to a specific timeframe.
- Look for Anomalies: Check for illogical changes.
- Track Over Time: Make this a regular exercise.
Automation Across the Network, for Free: Scale with FiVerity
- Sign Up: Register for FiVerity's free platform.
- Upload Your Data: Import datasets via persona lookup or bulk CSV upload.
- Automate: FiVerity will scan for matches, saving you time and effort.
Whether you're a DIY fraud analyst or looking to leverage automated systems, understanding the nuances of financial fraud and employing tailored strategies can enhance your fraud prevention efforts significantly. With FiVerity's platform, you can scale these tactics across a vast network, making your institution more secure and staying one step ahead of the fraudsters.